The page URL optimisation relates to the optimisation of the links displayed in search results alongside the Page Title and Meta Description, making it one of the most important Organic Ranking Factors. Although more limited in their wording than other onpage elements, they can add additional layers of information to the context of the Landing Page it represents.
Just like in the case of Page Titles, Page URLs rely on keywords to help the search engines determine what the Landing Page is about. However, a more important role is played by its structure which is used to define the relationship of the landing page to other pages on the website. This emphasises the importance of giving equal weight to the Keyword Research process as much as to the definition of the website’s Information Architecture and website taxonomy, ensuring these factors work together from the very beginning.
Unlike in the case of other onpage elements, the continuous optimisation of URLs is somewhat more difficult as they are placed within a website structure. This means that decisions made on the optimisation of one URL may often have implications for whole categories or even the entire website. Therefore, the most important aspect of a URL structure is ensuring each URL accurately represents the position its’ landing page occupies within the website’s information architecture.
Writing Optimised URLs
Along with Page Titles, page URLs are used by Search Engines in determining what Landing Pages to show for what keywords. So above all, the Page URL must be descriptive of the landing page it represents and in line with the Page Title and Meta Description for that page. This implies that the choice of what keywords to use for what landing pages must be driven by the same Keyword Research process used to define the Page Titles and Meta Descriptions.
Depending on the Landing Page, one must consider such Keyword Metrics as Organic Rankings, Search Volumes, Keyword Difficulty, estimated click-through rate and Traffic Potential to make judgements on what keywords to give preference to over others. Furthermore, this refers as much to the URLs of static Landing Pages, as to the Filenames of additional resources loaded by the browser from the given Landing Page.
URL Use of Words, Numbers, CAPs, Characters and Symbols
Depending on the website’s ability to outrank its SERP competition, the URL should use the head terms the Landing Page is targeting, preferably in a more concise manner. In the case of two similar URL options, all things being equal, the version featuring the most important keywords at the beginning should be preferred to that featuring them at the end.
One of the most important characteristics of a URL is timeliness. When writing a URL, it is not only important for it to be relevant but also to remain relevant further down the line. Thus, the use of dates in URLs should and is allowed. However having a date in the URL is only relevant when one of the most important aspects of the landing page is, in fact, its’ timeliness. The easiest way to determine whether there is any value in having a date in the URL is to understand whether the head keywords for the landing page it represents are searched in conjunction with a date.
This is often the case for events or time-bound information. Having said this, if a landing page contains information which is not necessarily time-bound, having a date in the URL (such as a publishing date) is more likely to subtract rather than add value to the URL. The publishing date is important and is, in fact, understood and used by search engines in determining what pages to show and when. However, the URL is not the best place for it to be displayed in.
It’s worth noting that URLs are case-sensitive, meaning a single capital letter in a URL can result in a Duplicate Page. This is why it is generally recommended for all URLs to use only lowercase letters, even for acronyms which are normally written in uppercase letters. Ensuring all URLs are lowercase from the very beginning can save a good amount of work down the line, when duplication issues would require each URL using uppercase letters to be redirected or used with a canonical tag, both options being far from ideal in the long run.
The use of non-English characters in the URLs of non-English websites is allowed and in most cases, should be encouraged. Even though non-english characters would require to be encoded, major search engines can recognise, crawl and rank web pages based on words containing them. So, if one expects users to search for keywords containing non-English characters, it is only normal to make appropriate use of them in URLs.
The character with arguably the most important reserved use in URLs is the forward-slash (/), used to employ folders and subfolders in storing landing pages. In simple terms, forward slashes (/) enable all URLs to be part of a hierarchy, by delimiting separate entities on a website from each other. An entity that is contained between 2 forward slashes (/) in a URL is called a Subdirectory (or subfolder), while the entities that are contained within Subdirectories and don’t generally end with a forward slash (/) are called Landing Pages.
Some subdirectories can employ the role of Landing Pages. It may also be worth noting that the absence of a slash at the end of the landing page section of the URL is a mere formality and not an indicator of whether it is indeed a landing page and not a subdirectory. Cases where forward slashes are used on both ends of the Landing Page portions of the URL are not infrequent.
The notable difference between the two is the fact that Subdirectories are employed to store Landing Pages the content of which have associated semantic meaning. In other words, the section following the last forward slash in the URL stands for the Landing Page, all other sections encapsulated on both ends by a forward slash are subdirectories which host that particular Landing Page.
Traditionally, the space in-between the words within URLs was filled by either hyphens (-) or underscores (_), however the former now occupies the space of the only recommended option. The reason behind this is that at the moment the major search engines are programmed to read the hyphens (-) as word separators, while the underscores (_) as a means of combining words. The use of hyphens, however, should be discouraged altogether.
An important feature in URLs is triggered by the use of hashes (#), which normally indicates not only the location of the page but also a specific location within the page itself, such as a header or the beginning of a paragraph on that page. This is particularly useful for information-heavy websites, which on some occasions may require to accommodate referrals to specific paragraphs or sections of text as opposed to entire landing pages. For this reason, the use of hashes is recommended to be used for this purpose only, as to not make this practice more complicated than it already is.
It’s worth noting that the content of such URLs with hashes (#) in them is not indexed, as the content is considered to already be part of the larger web page (held by the URL without the hash (#)). This prevents duplication issues from happening but also means this function must be used according to its intended purpose of showing a location within a page and by no means treated as a way of storing unique content.
When it comes to URLs, not all characters are born equal. It begins with a group called unreserved characters. As a starting point, the most commonly used characters in URLs are alphanumerics (a-z and 0-9). There’s also a small number of additional special characters including the hyphen (-) used for separating words, the underscore (_) previously used to combine words, the dot (.) and the almost equals sign (~). These symbols do not require encoding, which means that all URLs written using these characters will appear in browsers exactly as they are written on the backend.
On the other end, there are reserved characters, which possess a reserved technical purpose within a URL. This is most commonly found in the practice of automatically-generated URLs. In other words, their appearance in a specific part of the URL has the technical capacity to change its semantics. The full list of reserved characters include: ! * ‘ ( ) ; : @ & = + $ , / ? % # [ ]. Reserved characters can be used without encoding, but only when employed for their reserved purpose. Thus, only alphanumerics, the additional special characters “- _ . ~”, and the reserved characters used for their reserved purposes may be used without the need to be encoded.
All other characters (including reserved characters used outside their reserved purpose) are required to be encoded in order to be used in URLs. This practice is called URL encoding (percentage encoding) and stands for the replacement of characters with one or more character triplets that consist of the percent character “%” followed by two hexadecimal digits. For instance, when using the ampersand (&, which is a reserved character) as an abbreviation for “and” (which is a purpose other than the reserved purpose), one must encode them as %26.
Optimal URL lengths
Similarly, given the more restrictive nature of URLs, it is generally advised to keep them as short as possible, providing just enough information to understand the context of the Landing Page it represents on the website. As a general rule, this shortening should be attained by avoiding using superfluous words that do not add immediate value, like prepositions and conjunctions. It can also be achieved by avoiding the repetition of keywords that are already present in the categories and subcategories of the URL path.
A general recommendation is to keep the length of any given subdirectory or landing page URL segment within three words. The reason behind this is that the length of the URL can soar exponentially with each additional subdirectory it becomes a part of. So not only does it affect the risk of the URL being truncated in search results, but also becomes unintelligible to users who are less likely to rely on it to make a decision about the context of the Landing Page it represents.
In fact, there is a negative correlation between the length of a URL and organic search rankings, meaning that all things being equal, shorter URLs are more likely to rank in organic search results. There are a number of technical and practical considerations that make the length of a URL a topic of its own. From a technical point of view, URLs must be shorter than 2,083 characters in order to correctly render in all browsers. However, in order for a page URL to display fully in SERPs, as opposed to it being truncated, its length should be within the limits of 512 pixels.
The actual number of characters will, of course, vary as some characters spread over more pixels than others. A general estimate for URLs to fully display in SERPs would fall at around 50 to 60 characters.
Optimising the Landing Page URL in WordPress
There are still a number of things to consider when optimising the URLs of any given Landing Page. But as you will find the setting of URL structure and other things are mostly set up once and then reused across your publishing. There is one single thing that you will have to optimise every time you publish a new page or post and that is the URL slug or the last portion of the URL in the URL path.
Just like in the case of Page Titles and Meta Descriptions in order to edit your URL slug, you will need to go to RankMath icon in the top right corner of your Screen and click it. Once you click that the “Preview Snippet Editor” will open allowing you to edit the most important metadata for the page, including the URL permalink.

Optimising URL structure
A URL structure consists of a protocol, a preferred domain (also known as canonical domain), an optional subdomain, a domain name, a top-level domain, and a path, which may include one or several subdirectory levels (categories) used to specify the location of a landing page on the website, that in its own turn may contain a file extension for fixed URLs or one or several sets of URL parameters for dynamic URLs.
Referring to URL paths in particular, one must take note of website taxonomy and hierarchy which entails appropriate use of categorisation of content and information architecture. Website taxonomy gets particularly complicated with the use of dynamic URLs, which may cause a range of issues that may sometimes require to be tackled individually.
The structure of a URL
The protocol specifies the manner in which a browser is expected to retrieve the information from a resource. The web standards are (HTTP) (Hypertext Transfer Protocol) and HTTPS (Hypertext Transfer Protocol Secure) which can be defined as specific structures for transferring and receiving information on the web, most frequently used to retrieve HTML web pages. The notable difference between the two is that HTTPS uses an SSL (Secure Sockets Layer) certificate that facilitates the encryption of information, ensuring it can only be accessed on either the sending or the receiving end and never in between.
This enforces a level of protection over the user information from any unwanted third parties, including hackers or malicious applications designed to capture user data. It also prevents unauthorised third parties from using advertising on your website, often employed by free wifi networks.
As a result of its enhanced security, HTTPS websites get a lock icon in the browser window alerting users that their information is being protected, giving just a small additional level of credibility to the website. Lastly, it is required for the implementation of accelerated mobile pages (AMP) and is favoured in analytics, as it tracks referrer data with greater accuracy. For these reasons, it is currently believed that major search engines have a slight preference for HTTPS.
The preferred domain (canonical domain) specifies the version of the preferred domain (www or non-www) that precedes the domain name. To be technically accurate the www version of a website actually means the website will be placed on the www subdomain. Although there is no set preference by Search Engines for either one of these options, only one single version should be used across all the URLs on the website for consistency purposes. In order for this to work, all internal links must point straight to the preferred version as well as all the website URLs must be written using the preferred option, this also extends to the URLs used in the website code and the sitemap.
It is generally recommended to have permanent (301) redirects set up to the preferred version from the other one, even when only one of them is used across the website. In cases when the preferred version is not clearly specified, Search Engines may treat the two versions of the same page as references to separate pages, resulting in duplication issues. Although Search Engines do not give preference to any one version over another, one argument against the www version is that it serves no functional purpose, while the non-www version makes for a shorter URL, allowing more space for what may, in fact, be important.
A subdomain also referred to as a third-level domain is part of the original domain name and top-level domain, with a certain degree of autonomy, traditionally employed for such purposes as blogs, internationalisation, forums, career sections, and even product lines. However, with the advent of SEO, and particularly the fact that different subdomains are now treated as entirely different websites from each other or the top-level domain, their application has become increasingly more limited in favour of subdirectories (subfolders).
It’s only logical that the application of subdomains has now been reduced to sections that are clearly outside the scope of the website or when representing different business verticals that have little in common outside their brand name. Subdomains may be useful as a tool for enhanced user experience, delimiting certain sections of the website from its domain name. They may also be useful in particular for websites that cater to numerous but fragmented audiences and intend to build authority in these niche markets with inbound links coming from sources relevant to one subdomain but not to the rest.
One may argue that subdomains may also occasionally be used for targeting particular keywords, which may be impossible to do as part of the domain name, however, it must be noted that usually the cost of this is far outweighed by the impact. Lastly, subdomains can be especially great for testing a new design, UX and content elements on a website without the fear of it being out of touch with the rest of the website or for what it’s worth, having a negative influence over the organic search performance of the main domain.
A domain name is the snippet of text in between the preferred domain (or subdomain) and the top-level domain and is most commonly associated with the brand name. The domain name is the part of the URL that is most difficult to change, hence the importance of choosing domain names that last. Although historically, the domain name could have a drastic influence on SEO through the use of so-called exact match domains (EMD) targeting a head keyword, this was short-lived.
In fact, search engines have developed algorithms that would address the injustice caused by exact match domains (EMD) selected merely for their keywords, thus diminishing the power of websites to rank for keywords based on domain names. It’s worth noting, however, that while EMD algorithms have taken the power away from exact match domains, it has placed a strong emphasis on the branding factor to replace it. This has shifted the domain name game to the simple practice of selecting the right brand names, that make sense, are distinguishable in SERPs, and memorable to the users.
Although the choice of a domain name should be mainly driven by the branding factor, all things being equal, shorter domain names should be preferred to longer ones. As a future-proof practice, it’s also a good bet to avoid any kind of special characters, including hyphens (-). Domain names are unlike any other segments of a URL in their capacity to encourage repeat visits from SERPs. It is not an overstatement to say users rely heavily on domain names in making judgements on the credibility of information and the repeat click-throughs to the website.
A Top-level domain (TLD), also known as a domain suffix refers to the segment that follows the domain name, separated by the dot (.) and is the last URL element ahead of the URL path. Top-level domains can be either generic such as “.com” for commercial businesses and “.org” for organisations or country-specific, such as “.co.uk” for the United Kingdom and “.de” for Germany. Some top-level domains can fall under both segments, such as “.ac.uk” for universities in the United Kingdom only.
There are currently more than a thousand registered top-level domains, with some being more popular than others. The choice of which top-level domain to use will depend on the specifics of the website, with nearly half the registered domains using the “.com” extension. It’s worth noting that as new top-level domains are released, it provides the opportunity to choose domain names that were previously occupied on existing top-level domains, particularly those incorporating important keywords. However, this should be approached with caution as less-popular top-level domains can be associated with spammy websites.
Additionally, when choosing a Domain Name on a less popular top-level domain for the reason of it being occupied on other top-level domains, one may run into difficulties with branded search. Ensuring one can access your website by simply typing your brand name in the search box is far more important than having a catchy domain. It is therefore generally recommended to use the more established top-level domains unless an alternative one provides some brand value that the ordinary ones do not.
In the case of websites that are tied geographically, it is wise to use an appropriate domain suffix to indicate that. Not only will this be used by users when deciding on a website and which generally prefer local domains, but also by search engines that understand the differences in top-level domains. Some international websites targeting multiple geographical areas and languages take this one step further by using one domain name spanning across multiple top-level domains, with websites being interlinked through alternate tags that identify them as belonging to the same entity. This is especially common for large e-commerce websites that target distinct geographical markets using different languages.
A URL path contains one or several subdirectory levels (categories) and can be of two kinds: static, used to specify the permanent location of a landing page on the website that may also have a file extension and dynamic, containing a set of URL parameters that determine what content will show on the page. Subdirectories are made up of website categories and tags and can span across multiple levels, separated through a forward slash (/) in URLs.
Technically, subdirectories and categories are most often treated as synonyms, leaving the website tags in a place of their own. However, as far as URLs are concerned, to be entirely accurate some website tags can also be treated as subdirectories as long as they are represented by URL subfolders in the URL path and act on the website as categories. The main difference between a website category and a tag is that a landing page can be part of only one category, but can have multiple tags.
It’s also worth noting that subdirectories and subdomains were at one point used as substitutes, however, unless your website falls under one of the previously mentioned exceptions you’d more likely be recommended to use a subdirectory, as opposed to a subdomain.
Traditionally, landing pages used to have file extensions for HTML (.html and .htm), for scripts (.php, or asp) and images (.jpg or .png), however, it wasn’t long until they became obsolete. Major search engines would now recommend keeping your file extensions out of the URLs in order to make them more readable to users.
Lastly, unlike static URLs, dynamic URLs or URLs that are generated automatically based on selected content use so-called URL parameters, following a question mark sign (?) to indicate its beginning. URL Parameters are used to display dynamically generated content and are often used on large e-commerce website using so-called faceted navigation, where such functions as advanced categorisation, cross-filtering, and ordering may be necessary.
The choice of using dynamic URLs over static or vice versa will depend on the website specifics and should be investigated as a topic of its own. It may be worth noting, however, that the practice of disguising dynamic URLs as static is on its way up, mainly employed to make the URLs more readable to the user.
The hierarchy of a URL structure
The purposes and sizes of websites vary greatly over the web, and therefore so do their URL structures. While some are given the preference for a flat hierarchy structure having only one or two levels of subdirectories, others may require more vertical hierarchies to ensure an accurate representation of a website’s information architecture. As a general rule, UX best practice would recommend a homepage to lead to the main pages of the website within 3 interactions, so the maximum appropriate number of levels for categories should be limited to 3.
Having more than 3 levels of categories generally complicates the experience for the users and should be used only when it, in fact, adds clear value to the UX. In order for page URLs to be able to show the wider context of their landing pages one must make good use of subdirectory structure.
A subdirectory structure stands for the relationships between all website categories and tags. The closer a category is to its domain and the more relevant associated subcategories and landing pages it has, the higher the authority it is assigned within a website by the search engines. An adjoining aspect of this is a proper use of taxonomy, designed to ensure related content pages are grouped around meaningful topics that can be of additional value to SEO.
Categorising landing page URLs
Like in the case of Page Titles and Meta Descriptions, URLs must be descriptive of the Landing Page they represent but also make sense in relation to each other. In other words, if an information website lists all its Landing Pages with little regard to taxonomy, it hardly enables users to effectively interact with the website content.
On the other hand, when a Landing Page is listed under one broader category or several subcategories directly linked to its topic, it gives the user a sense of where they are on the website, encouraging them to go back and forth and interact more freely with the wider information context of the website. Not only is this beneficial to the user, but also to the search engines which place a significant emphasis on understanding these onsite relationships and user interactions over time.
Better yet, Search Engines have learned to establish relevancy signals for Subdirectories based on the kind of Landing Pages they host and vice-versa, so designing appropriate content taxonomies can go a long way in uplifting the website at large in search results. To sum it up, a healthy URL taxonomy enables search engines to better understand not only the content of particular landing pages but entire sections and the website as a whole, uplifting its overall ability to rank in organic search results.
Using subdomains vs subdirectories
The word from the Search Engines is that they treat subdomains and subfolders equally, at least as far as crawling and indexing are concerned. However, taking a closer look at their own comments, this couldn’t be further from the truth. Although search engines have learned to crawl and index subdomains at the same speed and convenience as the subdirectories, several differences between the two define the difference in their application.
Subdomains, in particular, are treated by search engines as separate entities with their own relevancy, trust and authority signals from Search Engines, independent of their domain. Subdirectories, however, remain tied in these regards to their domain, which explains why they are the option of choice, most of the time. Unless the website’s sections or business verticals are so distinct from each other that they won’t benefit from the inbound links coming to the other sections, the recommended option is to use Subdirectories as opposed to Subdomains.
When trustworthy, authoritative links lead to a Subdirectory of a website, they also impact the authority of other subdirectories and the wider website. Thus, unlike in the case of subdomains, having the content spread over subdirectories allows for the authority, trustworthiness and relevancy signals used by search engines to be shared across the wider website.
Using dates vs topics as subdirectories
Although dates are acceptable in URLs under select circumstances, this refers only to landing pages and not so much to subdirectories. The reason behind this is that the content on some landing pages might be time-bound and searched using keywords incorporating dates, thus making the dates a relevancy signal for search engines about the landing page. This does not extend to subdirectories, because they are meant to be permanent to a website and define the context of the Landing Pages that reside under it.
The only plausible exception could be for websites that host numerous events and have the necessity of grouping them by dates. However, even in this case, the website would end up with whole sections that will hardly get any visits after their timing has passed, which means it must be approached with caution and likely some additional measures to tackle this. In all other situations, however, the dates provide limited context as far as the Search Engines or users are concerned and thus should be avoided in subdirectories altogether, in favour of descriptive topic-based categories.
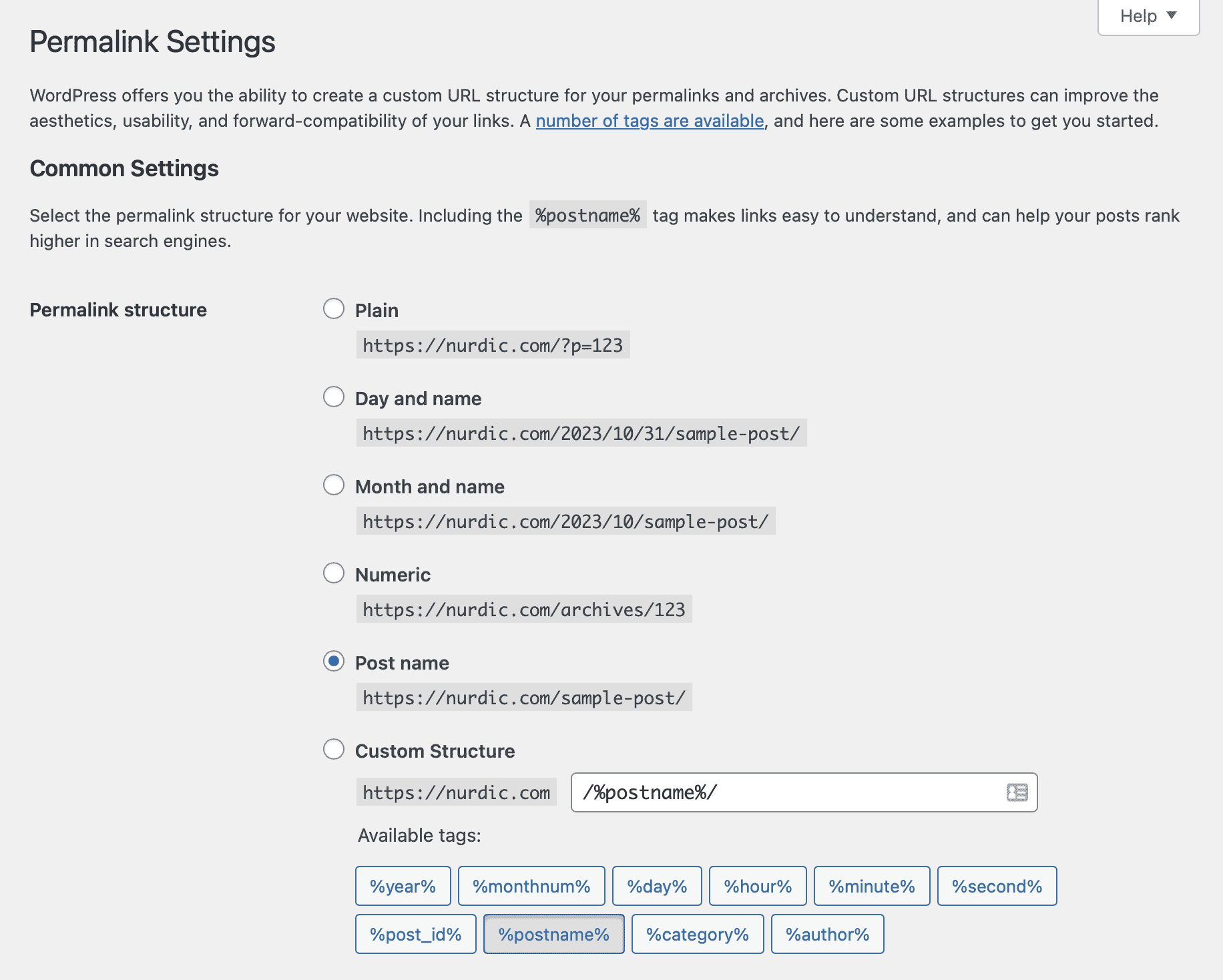
Changing the Permalinks Settings in WordPress
If you’re just starting a blog or even if you already had one for a while but still have your dates displayed in the URL, it’s likely because of your Permalinks structure which is editable in WordPress. Your Permalinks structure allows you to set how your URLs will be structured and displayed.
To change your Permalinks settings in WordPress navigate to “Settings”, then click “Permalinks” which will open the “Permalinks Settings’” window. The quickest fix is to change your Permalink Structure to “Post name”. This way you will have search engine optimised URLs by default.
Using Static vs Dynamic URLs
The static and dynamic URLs are as much alternative as they are complementary approaches to looking at web pages, with the latter being significantly more difficult to handle, for SEO purposes or as the technical skills are concerned. Although dynamic URLs are often favoured by web developers and analysts, they actually negatively influence both SEO and the user experience, explaining the presence of such a vast amount of tactics and methods that are used to tackle the implications that come with them.
A Static URL is used to store the address of an HTML page on a server and deliver it to the users over and over again, exactly as it was stored. Its distinguishing quality is that it remains the same over multiple user requests of that page unless it is manually changed.
A dynamic URL is the address of a dynamic web page that contains server-side code which generates unique content each time it is loaded, as opposed to it remaining the same over multiple user requests. A dynamic URL’s distinguishing quality is that it may change depending on the page results from the search of a database-driven website.
The use of dynamic URLs is especially common on large e-commerce websites that contain a high number of products, with categories that require to be updated virtually in real-time. It’s also especially relevant where there’s an increased number of product specifications that are used in categorising, cross-filtering and re-ordering of website content. This concept is known as faceted navigation and allows users to choose a selection of products based on selected pre-defined filters. In such cases writing optimised static URLs by hand may seem too time-consuming, often unnecessarily sophisticated or even impossible, arguing the value of URL parameters and the wider use of dynamic URLs.
The server-side code of dynamic URLs is triggered by the so-called URL parameters, which are also known by the aliases of query strings and URL variables. URL parameters are the segments of the URL that follow a question mark (?). They are comprised of a key and a value pair, separated by an equal sign (=), and can be used in multiple numbers in a single URL with the help of an ampersand (&). URL parameters may serve a number of purposes, such as web tracking, re-ordering and filtering of content, identifying content based on certain characteristics, paginating, searching, and translating.
The major search engines have expressed that dynamic URLs are crawled and indexed in the same manner as the static URLs and are therefore not an issue as far as the crawl-ability and index-ability of content is concerned. However, there are several aspects that make this practice challenging from an SEO perspective.
- The most widespread issue associated with the use of dynamic URLs is duplication, often caused by a change in URL parameters that essentially leads two or more different URLs to show pages with highly similar or virtually identical content. This is the case for URLs using web-tracking parameters, as they change the URLs at hand even though their content remains the same, thus resulting in duplicate pages. This is also true for URL parameters used to re-order the content of a page. Because, although in a different order, the content of the two or more pages is essentially the same, and as a result, the pages represented by all their URL versions will be treated as duplicates. This may also occur with URL parameters that are used for identifying information, as these options are often represented by stand-alone category pages on the website. Occasionally, this can reflect over the filter parameters when a pre-defined filter option matches or is very similar to a website category. When URLs feature pagination parameters spreading content over multiple pages while having a “view all page”, it becomes problematic as each page of the sequence will use content also present in the “View all page”. Although not always, URL parameters used for on-site searches may coincide with website categories, thus yet again leading to duplicate issues. Also, when using URL parameters to show different languages on the website, particularly in cases when navigation elements are translated into a different language while the page content remains the same, the page variations will be treated as duplicates. Lastly, having URLs with not one but two or more URL parameter pairs may lead to duplicate versions of web pages caused by the order of URL parameters in the URL.
- Thin content issues caused by URL parameters are generally related to duplicated content but are different in the fact that website pages are not as much alike as they are empty or incomplete. This can be the case for identifying, filtering, searching and pagination parameters when they lead to pages that have little to no actual content or results.
- Search Engines tend to crawl and index websites at impressive speeds, but even they have limitations. This is felt particularly in the case of large websites that are updated regularly and need to be re-crawled. Thus, the notion of crawl budget comes in to define the capacity of search engines to crawl and index websites over time. The more variations of web pages are generated as a result of varying URL Parameters, the more of the crawl budget is drained without valuable contribution to the website being fully crawled, indexed and frequently updated.
- Another issue that comes hand in hand with duplication is the split of organic ranking signals. This happens when the authority signals coming from inbound links from other websites to different versions of the same page are not consolidated but split among these pages. In simple terms when a search bot crawls several similar versions of a page, these pages end up competing for the same keywords, leaving each of them in a weaker position against competition if compared to one singular version.
- Lastly, URL parameters make URLs less readable to the user that are less likely to rely on them to make a click-through decision. Not only does this have a negative effect on the click-through rate to the website from search results, but more recently this has also been associated with negative brand engagement as these URLs are seen in SERPs, reach social media websites, or even emails and messaging apps.
All these issues are the product of parameter-based URLs that once changed, are treated as new pages, becoming multiple variations of the same page, targeting the same keywords, flooding the SERPs, offering limited value to users and draining the crawl budget. It’s worth noting that the most problematic aspect of using dynamic URLs isn’t so much the issues caused by individual URL parameters, which can be easily tamed, as it is the sheer variety and volume of issues that may overlap and often become difficult to predict or control.
While this is unlikely to result in a penalty or entirely remove a website from organic search results, it will often decrease the overall quality of the website and each web page in particular in the eyes of search engines.
Parameter-based URLs are by far the most unpleasant aspect to deal with in optimising URLs for search engines, making it the very aspect that, given the right implementation, can give a website its’ competitive edge. There are a set of considerations to take into account when moving forward with taming the issues caused by URL parameters which should be implemented in a specific order, a manner that allows the process to be structural and manageable over time.
This order will depend on the specific URL parameters that are used on the site, the priority of issues depending on the specifics of the website, and some of the options can work together while others are not compatible.
Before moving forward with tackling the URL-parameter issues, one must ensure to use of static URLs wherever possible, leaving parameter-based URLs only for sections that truly require it.
It then begins with the correct implementation of pagination, as it may reflect on all other parameters when used as part of the same URL. The second task is, then, limiting the actual number of parameter-based URLs, where possible. For tracking, identifying and reordering parameters, the use of canonical tags can help with the consolidation of ranking signals for duplicate pages, giving some degree of control over the URL versions to be indexed and displayed in organic search.
For even greater control over all parameters, one may further investigate the potential issues and configure the way the parameters are handled directly in the search console or webmaster platforms for each search engine in particular. This is especially relevant for filtering parameters, used for faceted navigation, as it may lead to a large number of pages with overlapping content that are neither duplicates nor unique, defining the importance of these pages to be understood by search engines.
The only downside here is that if the website targets multiple search engines, one must use a different platform for each one to configure the handling of parameters. Lastly, especially in situations where the crawl budget is of particular importance, one can use robots meta tags or a robots.txt file, to control the manner in which all parameter-generated pages are crawled and indexed by all search engines.
Implementing pagination
When a website page needs to display a list that ranges in tens, hundreds or thousands of items, it becomes complicated as far as the UX part of a website is concerned. Thus, it is usually split into a number of sequential pages, each with its own URL, using pagination. These sequential pages are irrelevant for organic search in the respect that hardly any user searches for the second or any of the consecutive pages of a list, but they are still crawled and indexed by search engines.
This justifies the necessity to explain the nature of these pages and the relationship between their URLs, which are part of the same sequence, to the search engines. As it happens, the search engines are currently capable of distinguishing these types of pages on their own, but some, however small, additional value may still be obtained by not leaving the manner in which a website is crawled and indexed fully in the hands of a search engine bot.
It begins with the use of rel=”next” and rel=”prev” link attributes as part of the head section of the page only, to indicate the following and the preceding pages of a sequence, respectively. Thus, page 1 (also known as the root page) of the sequence will only have a rel=”next” link attribute, while the last page of the sequence will only have a rel=”prev” link attribute, and all pages in between will have both.
If the URL uses other parameters in addition to pagination, it’s only normal that one must include them in the rel=”next” and/or rel=”prev” link tags to accommodate this. Search engines treat pagination markup only as a strong hint as opposed to a directive, which is expected to consolidate the ranking signals of a sequence of pages to the root page (page 1), making it the page that shows up in search results most of the time.
Search engines may still sometimes rank numbered pages in search results, when other ranking factors overpower the importance of this relationship, but all other things remaining equal between the numbered pages, search engines will very likely favour the first page.
Pagination has been around for a long time during which the industry managed to produce a number of implementation techniques that have become outdated, misunderstood or are simply plain wrong. These techniques may actually be of great value in determining potential issues around pagination for existing websites and justifying an SEO intervention.
Limiting the number of parameter-based URLs
The second task is, then, limiting the actual number of parameter-based URLs by eliminating unnecessary parameters, preventing URLs that use empty values as part of parameters, allowing the use of multiple values with a single key, and defining an order for how URL parameters should be presented in URLs.
This can be achieved firstly, through the elimination of unnecessary parameters, or in other words, parameters which serve no actual function. This is often referred to as parameters caused by “technical debt”, which historically served a function but have been subsequently replaced. The most common example of this is session IDs, used for web-tracking in the past but being replaced by cookies.
Secondly, preventing the URLs with parameters that have empty values. Thus omitting URLs with URL parameter keys that have their parameter values blank will further reduce the number of unwanted URLs.
Thirdly, when using a parameter key with multiple values, make sure the parameter values are used together after the single key, as opposed to each value having its own key. This prevents potential duplication issues further down the line when depending on the order of key and value pairs, you may have multiple URLs for essentially the same page. Not to mention, this helps with shortening the URL which beneficially reflects on click-through rates and search engine rankings.
Lastly, ordering URL parameters by using a script to place them in a consistent order, regardless of how the users select them will further ensure that no additional duplicate URLs will be generated as a result of a different order of parameters within it. Although having multiple versions of URLs generated by a different order of parameters will lead to duplicated pages, this issue can be easily tackled by most search engines assuming they understand the parameters. Nevertheless, this remains a concern because the additional number of URLs will put a strain on the crawl budget and potentially lead to split ranking signals.
This contributes to tackling all 5 major issues caused by URL parameters, addressing the duplication of content, improving the efficiency of the crawl budget, consolidating the ranking signals into fewer pages, and in some cases even making the URLs shorter, with beneficial effects on the click-through rates.
After all, the best way of fixing the issues caused by URL parameters is to prevent them from happening, with which this strategy should help. However, this is unlikely to fix all issues caused by all URL parameters, as different parameters have different functions, causing issues that may differ in their nature and therefore require independent attention.
Using canonical tags
The canonical relationship between URLs predisposes that website users will continue to have access to multiple URLs for web pages that use these parameters while instructing search engines when any of these pages have one or multiple identical or highly similar alternative pages as well as which page among them is the preferred version. It’s worth noting that apart from canonical tags, search engines use a number of additional factors in determining which page should be treated as canonical among a number of highly similar or identical pages.
To interpret this just right, it means search engines understand the website’s preference as to which of these page URLs the consolidation of ranking signals should go into, and thus which version of the URL is preferred to be shown in search results, but they will only treat it as a contributing, often decisive, factor to this decision and not a directive.
As a consequence, search engines may and do end up using other than canonical URL versions to consolidate ranking signals, showing them in search results as opposed to those which the canonical tag points to, but all other things being equal between the two or more pages, this is more of an exception than a rule.
- Because the implementation of pagination comes first in taming URL parameter issues, when implementing canonical tags, one must begin with the pages that use pagination parameters. This predisposes the use of self-referencing canonical link attributes, to supplement the already existing rel=”next” and rel=”prev” link attributes, defining that each of these pages that are part of a sequence are, in fact, unique pages. A very important point here is that when the URLs have other parameters in addition to pagination, they must be included in the above-mentioned rel=”next” and rel=”prev” link tags, but never in the rel=”canonical” link tags, as this practice would otherwise cause search engines to treat these pages as duplicates. As an alternative, the practice of using canonical link attributes to point from all sequenced pages to the root page (as opposed to that of using self-referencing canonical link attributes) may lead search engines to not acknowledge the content on any of the following sequenced pages. This, in its own turn, would reflect poorly on the consolidation of ranking signals, as search engines might ultimately end up seeing significantly less content. Additionally, the use of a View All page that lists all items from all paginated pages poses the question of how to handle it. Although, at some point, an option recommended by search engines, the choice of using canonicals on all sequenced pages pointing to the View all page, thus favouring it to show in search results instead of the root page (page 1) is far from ideal. The main reason behind it is that this can not be applied universally, being particularly problematic for very large lists, putting a strain on page loading times, thus negatively affecting SEO. Not to mention that it goes against the very function of canonical tags, which are meant to deal with pages that show virtually identical pages and not pages that have content which overlaps only partially.
- It continues with the building of a canonical link attribute relationship between the URLs that are duplicated based on tracking, identifying and reordering parameters. In this case, the canonicals are used for URLs with these three parameters because they are likely to generate pages that are identical or highly similar at worst, as opposed to pages that share some duplicate and some unique content. Canonical tags are, therefore, not suitable for URLs using searching, translating or some of the filtering parameters, as their page content wouldn’t be similar enough to the canonical as such.
Lastly, although it partially takes the strain off the crawl budget, as non-canonical pages will be crawled less frequently, supplementing canonical tags with meta robots tags or a robots.txt file will take it one step further to solve this issue to its fullest extent.
Configuring parameters in Search Console and Webmaster Platforms
Lastly, websites, where the crawl budget is of particular importance, may also ease the strain put on pagination URL parameters by setting up the pagination parameters in Search Console or Webmaster platforms for easier control over their crawling and indexing over time.
Using a sitemap
A sitemap can be as simple as a full list of a website’s public URLs. A sitemap’s purpose is to inform search engines about what’s available for crawling on a website, ensuring that all pages including those that may seem difficult to access for search bots are indeed properly crawled and indexed. It’s worth emphasising that a sitemap only lists the public pages of a website, thus excluding any pages that are behind the “log-in window” or which should not be made available to the public directly through a search engine.
Sitemaps are particularly useful for large websites that are updated frequently and thus are prone to delays in getting all pages crawled and indexed, websites that contain sections which are not very well linked together or websites with few inbound external links. Historically, several types of sitemaps were used, including HTML sitemaps, XML sitemaps, RSS feeds and text files, with XML sitemaps becoming on the rise over the last decade.
An XML sitemap can contain a maximum of 50,000 URLs and weigh no more than 50MB, numbers which may seem limiting to large websites. This is why sitemaps can be placed under a sitemap index under similar restrictions – each containing no more than 50,000 sitemaps and being under 50MB in size, but it’s worth noting you can have multiple sitemap indexes if your website contains more the 50,000 * 50,000 URLs, which is very unlikely.
For websites that have multiple alternate versions for different languages and/or regions, one may employ hreflang tags to specify the language and/or locale each URL is targeted toward, directly within sitemaps. This can be employed even for websites that extend to multiple domains or top-level domains (TLDs). In order for hreflang tags to work, each URL entry in the sitemaps must list all of its alternate versions, in a manner that forces every alternate version of a URL to point back to all of its other alternate versions.
This ensures that the ownership of all domains and their respective pages (and the consolidation of ranking signals among these pages) isn’t put into question by such cases when random websites declare their pages as being alternate to your own, with the intent of consolidating the ranking signals to their pages at your expense.
Keeping all the alternate versions of URLs up to date in sitemaps may become overwhelming, so in cases when it comes down to prioritising which versions to update first, the ones being served to users with different languages will come ahead of the ones being served to users from different regions. In other words, it’s more important to have your alternate tags for the “en” version set up to point to its “fr” or “de” versions, as opposed to its “en-gb” or “en-us” versions.
Similarly, search engines are not accustomed to deriving a web page’s language based on its set geographical region, but learned to associate a language with all geographical regions it is spoken in. In other words, if you’re aiming for simplified hreflang implementation in sitemaps, you may use the language code alone to target all the speakers of that language but have the option to restrict the targeting to certain geographical areas through a country code.
Big or small, an international website would also benefit from an x-default tag applied to the hreflang section in sitemaps that specifies the version of a URL to serve to those users whose browser settings are set to a language that is not specified through any of your alternate versions. This ensures that all users speaking a language other than one supported by the website will be directed to a “main” version of the page, which may be more suitable than any of the language-specific pages.
In addition to the option of using sitemaps for specifying alternate language versions of URLs, one may also employ sitemap extensions to list the locations of media files, including images, videos and other content which search engine crawlers may find hard to parse. Although optional, XML sitemaps allow for additional data to be included about the URLs, which may help ensure the website is crawled more effectively.
This includes such aspects as when the URL was last updated, how often it changes, and its relative importance to other URLs on the website. Similarly, sitemaps often work hand in hand with robots.txt files that serve exactly the opposite purpose – ensuring all private URLs are not crawled and/or indexed by search engines.
Using robots meta tags or a robots.txt file
There are a number of robots meta tags used to instruct search engines how to behave in regards to the pages they are used on. However there are 2 meta tags that address the crawl budget at the page level in particular, the nofollow tag and the noindex tag. Using a canonical tag for a set of URLs showing similar or identical pages ensures the duplicate versions of the page will be crawled less often, but canonicals are not applied universally across all parameter-using URLs.
In order to take the strain of the crawl budget completely one can use a meta nofollow tag, which gives a directive to search engine bots to not crawl the page. This often comes hand in hand with a meta no-index tag, which gives the directive to search engine bots to not index the page at hand, thus keeping it out of SERPs.
When it comes to pagination in particular, the use of a no-index tag is by no way a substitute or supplementation to the use of rel=”next” and rel=”prev” attributes, because it would prevent the consolidation of the raking signals (to the root page or otherwise). In the long run, the use of a noindex tag on paginated URLs may also lead search engines on a path of eventually nofollow the content behind them, which explains the next point.
Paginated URLs shouldn’t have a place for a nofollow tag either, as the content shown in all the paginated pages following the root page, may end up remaining undiscovered by search engine bots or dropped from SERPs as a result. Either of these tags will most often be used for the purposes of dropping paginated URLs from SERPs because they are of limited value or because the pages following the root page show up first, but this ends up being done at the expense of properly consolidating ranking signals to the root page.
When confronted with an issue of other than the root page ranking in SERPs, one must investigate the real causes behind it, as opposed to relying on noindex / no follow tags to fix it.
Disguising dynamic URLs as static
Dynamic URLs may seem somewhat unrepresentative of the landing pages they hold, particularly because of the use of so-called URL parameters. These can sometimes unravel to great lengths making the content of the URL more intelligible to machines but less understandable to humans. Thus these can be replaced by custom URLs through redirects. This way static seeming URLs hold a more descriptive function and are more useful to the customers.
It is, however, quite hard to correctly create and maintain rewrites that change dynamic URLs to static-looking URLs. It is also much safer to serve the original dynamic URL and let the search engine handle the problem of detecting and avoiding problematic parameters. The only recommendation for simplifying the URL is to strip it of unnecessary parameters while maintaining the overall structure of a dynamic URL.
If you transform your dynamic URL to make it look static you should be aware that search engines might not be able to interpret the information correctly in all cases. Thus, if you want to serve a static equivalent of your site, you might want to consider transforming the underlying content by serving a replacement which is truly static.
Custom 404 Pages
When a website visitor goes to a page that is no longer available, he or she is shown a 404 (not found) or 410 (gone) response page. This can be the result of them either following a broken link or typing in the wrong URL. Alternatively, it can also be the result of the content having moved somewhere else without proper redirects in place to account for it. These status codes indicate to search engines that the page doesn’t exist and the content should not be indexed. Creating a custom 404 page can be achieved by accessing your server’s configuration files.
Whatever the reason, a custom 404 page is meant to kindly guide users back to a working page, stating the potential causes for the broken flow which can greatly improve the user’s experience. A good custom 404 page can also point towards the information the users might be looking for and provide other helpful content that encourages people to explore the site further. Generally, a 404 page should state the following:
- Tell visitors clearly that the page can not be found
- Make sure the 404 and 410 pages have the same look and feel (including navigation) as the rest of the website.
- Consider adding links to the website’s home page and other important sections
- Provide a way for users to report the broken link.
There’s also a list of things to avoid when dealing with 404 (not found) and 410 (gone) pages, including:
- Ensuring the 404 pages are not indexed in search engines (make sure the web server is configured to give a 404 HTTP status code or, in the case of JavaScript-based sites — include the noindex tag when non-existent pages are requested).
- Avoid blocking 404 pages from being crawled through the robots.txt file (404 pages should have only a “noindex” tag, but not also a “nofollow” tag).
- Avoiding to provide anything other than only a vague message such as “Not found”, “404”, or no 404 page at all.
- Avoid using a design for your 404 pages that isn’t consistent with the rest of your site.
Handling Mobile URLs
With the increased demand for websites that cater to mobile users came the question of how to better structure them. If initially mobile websites were placed on a “m.” subdomain, in more recent times it became obsolete, all thanks to responsive design which allows the use of a single URL for both mobile and desktop websites.